
As you know, we are living in a world of humans and machines. For millions of years, we humans have been growing and learning things from past experiences. On the other hand, the era of machine and robots have just begun.
Now you can consider it in a way that currently we are living in the primitive age of machines, while the future of machines is enormous and is beyond the scope of imagination.
Now in today's world, these machines or robots have to be programmed before they start following your instructions. But what if machines started learning on their own from their experience working like us, feeling like us, doing things more accurately than us might even start a war of their own.
All around, your computers are making decisions, and those decisions affect your daily life. When you do an internet search or scroll through your news feed, computers decide what you see. Computers can already recognize your face, understand your voice and drive cars for you. So how is any of this possible?
In this article, we will talk about what machine learning is, the types of machine learning, the future of machine learning, etc.
What is Machine Learning?
You may have heard about something called AI or Artificial Intelligence, but true artificial intelligence is decades away. There's a type of AI called machine learning that is here today. It's a type of AI you probably interact with every day without even knowing it.
For example email filters, auto-complete text, video recommendations, digital assistants, translation apps, and voice recognition. And it has the opportunity to help us tackle some of the world's biggest challenges.
Machine learning is the science of getting computers to act, recognize patterns and make decisions without being explicitly programmed. What's so exciting is that it's a completely different way to program a computer than what we have ever done before.
With machine learning, instead of programming a computer step-by-step (the traditional way), you can program a computer to learn exactly as you learn through trial and error and lots of practice.
Learning comes from experience, and that's true for machine learning too. In this case, experience means lots and lots of data. Machine learning can take in any kind of data: images, video, audio or text and begin to recognize patterns in that data.
Once it learns to recognize patterns in the data, it can also learn to make predictions based on those patterns, like noticing the difference between an image of a car and an image of a bicycle.
AI and machine learning are playing a bigger role in society at large and shaping all of our futures. That's why it is so important to learn how it works with some hands-on experience.
Different Types of Machine Learning

Broadly speaking, all machine learning models can be categorized as supervised or unsupervised. We will uncover each one of them and what all types they have.
1. Supervised Learning
Supervised Learning involves a series of functions that map an input to an output based on a series of example input-output pairs.
For example, if we have a data set of two variables, one being age which is the input and the other being the shoe size as output, we could implement a supervised learning model to predict the shoe size of a person based on their age.
Further, with supervised learning, there are two subcategories. One is regression, and other is the classification.
1.1 Regression Model
In the Regression Model, we find a target value based on independent predictors, which means you can use this to find the relationship between a dependent variable, and an independent variable. In regression models, the output is continuous.
Some of the most common types of regression models include
A. Linear Regression
Linear Regression is simply finding a line that fits the data. Its extension includes multiple linear regression, which is finding a plane of best fit and polynomial regression, which is finding a curve for best fit.
B. Decision Tree

The decision tree looks like the diagram given above, where each square above is called a node and the more nodes you have, the more accurate your decision tree will be in general.
C. Random Forest
These are assembled learning techniques that build off over decision trees and involve creating multiple decision trees using bootstrap data sets of original data and randomly selecting a subset of variables at each step of the decision tree.
The model then selects the mode of all the predictions of each decision tree, and by relying on the majority winds model. It reduces the risk of error from the individual tree.
D. Neural Network
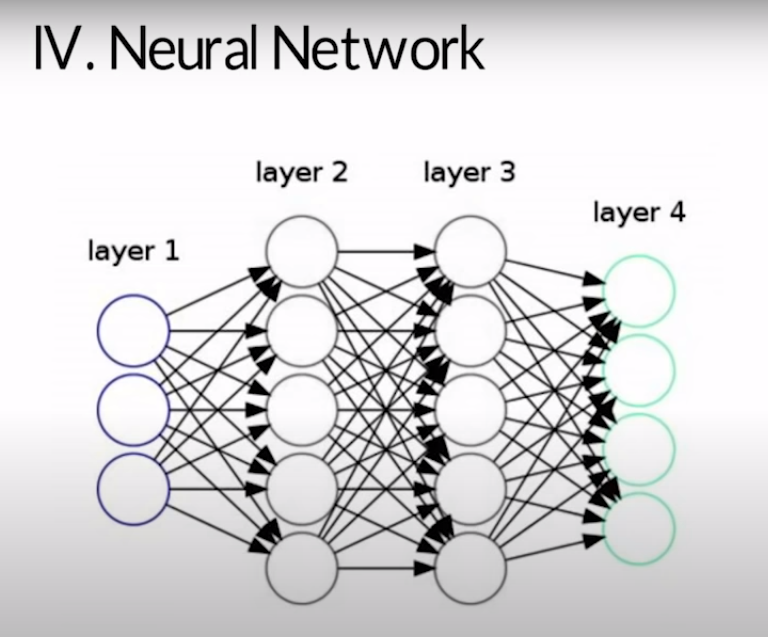
It is quite popular and is a multi-layered model inspired by human minds. Like the neurons in our brain, the circle represents a node. The blue circle represents an input layer, the black circle represents a hidden layer, and the green circle represents the output layer. Each node in the hidden layer represents a function that input goes through, ultimately leading to the output in the green circles.
1.2 Classification
In classification, the output is discrete. Some of the most common types of classification models include
A. Logistic Regression
Logistic regression is similar to linear regression but is used to model the probability of a finite number of outcomes, typically two.
B. Support Vector Machine

It is a supervised classification technique that carries an objective to find a hyper lane in n-dimensional space that can distinctly classify the data points.
C. Naive Bayes
It's a classifier which acts as a probabilistic machine learning model used for classification tasks. The crux of the classifier is based on the Bayes theorem.
D. Decision Tree, Random Forest and Neural network these models follow the same logic as previously explained. The only difference here is that the output is discrete rather than continuous.
2. Unsupervised Learning
Unlike supervised learning, unsupervised learning is used to draw inferences and find a pattern from input data without references to the labelled outcome. Two main methods used in unsupervised learning include clustering and dimensionality reduction.
2.1 Clustering

Clustering involves the grouping of data points. It's frequently used for customer segmentation, fraud detection and document classification. Common clustering techniques include k-means clustering, hierarchical clustering, mean shape clustering, and density-based clustering. While each technique has different methods for finding clusters, they all aim to achieve the same thing.
2.2 Dimensionality Reduction
It is a process of reducing the dimensions of your feature set Auto States simply reducing the number of features. Most dimensionality reduction techniques can be categorized as either feature elimination or feature extraction. A popular method of dimensionality reduction is called principal component analysis or PCA.
Future of Machine Learning
Artificial Intelligence is in a state of rapid change. Most companies that were evaluating or experimenting with AI are now using it. Machine Learning played a vital role in this advancement.
Machine Learning is a subset of AI which is based on the algorithms that improve automatically through experience. Various industries ranging from IT, finance, media, gaming, robotics, and manufacturing have already set Machine learning technology into practice.
ML's algorithm helps them understand how the products are being used so that they can customize them according to the customer choice on a large scale. Let's take Netflix for example. In order to recommend what you may be most interested in watching next, Netflix has deployed machine learning algorithms that associate your preferences with that of users with similar tastes. Another good example of ML is self-driving cars.
Machine Learning, however, is still in its very early stages. A lot of work needs to be done. In the future, machine learning will help to build self-learning robots and machines which are expected to improve their performance without using any human involvement. In this way, the machines can make decisions based on data by using the data from the past to predict future actions.
New robots are being designed to mimic the human brain using neural networks AI, computer vision and other technologies. With rapid advancements in AI and ML that can also become a reality.
Quantum computing is one such advancement which will give ML the capability to create systems that execute multistate operations at the same time by using the quantum property of superposition which will improve the processing of ML models. Computer vision will also provide the ability to identify and analyze data in form of graphics, videos, audio and images.
Machine Learning (ML) and Artificial Intelligence (AI) will continue to have a great impact on our lives in the future. The need of the hour is to maintain high-speed processing systems which will carry out ML-based algorithms with high accuracy and precision free from any biases.
This will make the creation of ML products a lot better but also more fun. With the improvement of ML tools, data scientists will be able to focus more on efficient ML model development rather than spending time on tedious production tasks.